Numerical Results
Temporal Stability
Method
Given a set of input videos of a human actor in motion, captured in a multi-view camera setting, our goal is to enable temporally consistent, high-fidelity novel view synthesis. To that end, we learn a 4D scene representation using differentiable volumetric rendering, supervised via multi-view 2D photometric and mask losses that minimize the discrepancy between the rendered images and the set of input RGB images and foreground masks. To enable efficient photo-realistic neural rendering of arbitrarily long multi-view data, we use sparse feature hash-grids in combination with shallow multilayer perceptrons (MLPs).
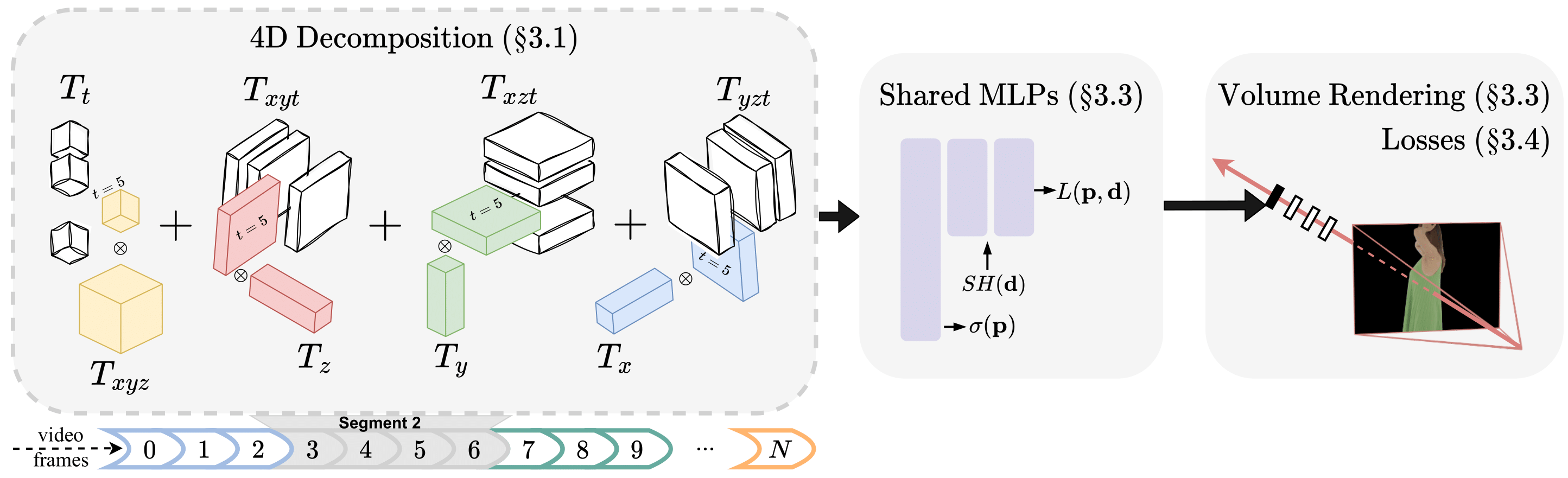
As illustrated in the figure above, the core idea of HumanRF is to partition the time domain into optimally
distributed temporal segments, and to represent each segment by a compact 4D feature grid. For this purpose, we
extend the TensoRF vector-matrix decomposition (designed for static 3D scenes) to support time-varying 4D
feature grids.

