How it works
At the core of Express‑2 is a tightly-coupled architecture built from three advanced models:
- Express‑Animate: a frontier foundation model for generating co-speech human gestures. Its core capability lies in producing anatomically accurate and temporally coherent motions driven purely by audio input.
- Express‑Eval: a CLIP-like model that plays a crucial role in evaluating the alignment between input audio and the corresponding generated human motion.
- Express‑Render: a Diffusion Transformer (DiT) that translates the motion cues from Express‑Animate into photorealistic video-frames of the avatar.
This modular design enables Express‑2 to generate avatars with remarkably life-like motion, precise lip sync, expressive body language, and robust visual fidelity across extended video sequences, addressing core challenges that enterprises have in long-form, controllable, and authentic avatar video generation.
Below is a system overview of Express‑2. Given an input audio, Express‑Animate generates multiple candidates for human motion that match the audio. Express‑Eval evaluates the quality of the motion and selects the best one. Express‑Render generates the avatar with the selected motion.
Express‑Animate
We developed Express‑Animate, a frontier foundation model for generating co-speech human gestures. Its core capability lies in producing anatomically accurate and temporally coherent motions driven purely by audio input.
While recent end-to-end approaches have demonstrated strong potential, they often come with substantial demands on data, compute, and training time. To address this, we intentionally decoupled motion generation from avatar appearance – splitting the problem into two more manageable parts. This design choice enables faster convergence and more targeted improvements within each submodel. Early in development, we also discovered that training a specialized model focused solely on human motion resulted in richer, more realistic gestures.
Without Express‑Animate, our avatars would lack the subtle, audio-synchronized body and facial expressions that make animations feel truly alive.
Express‑Eval
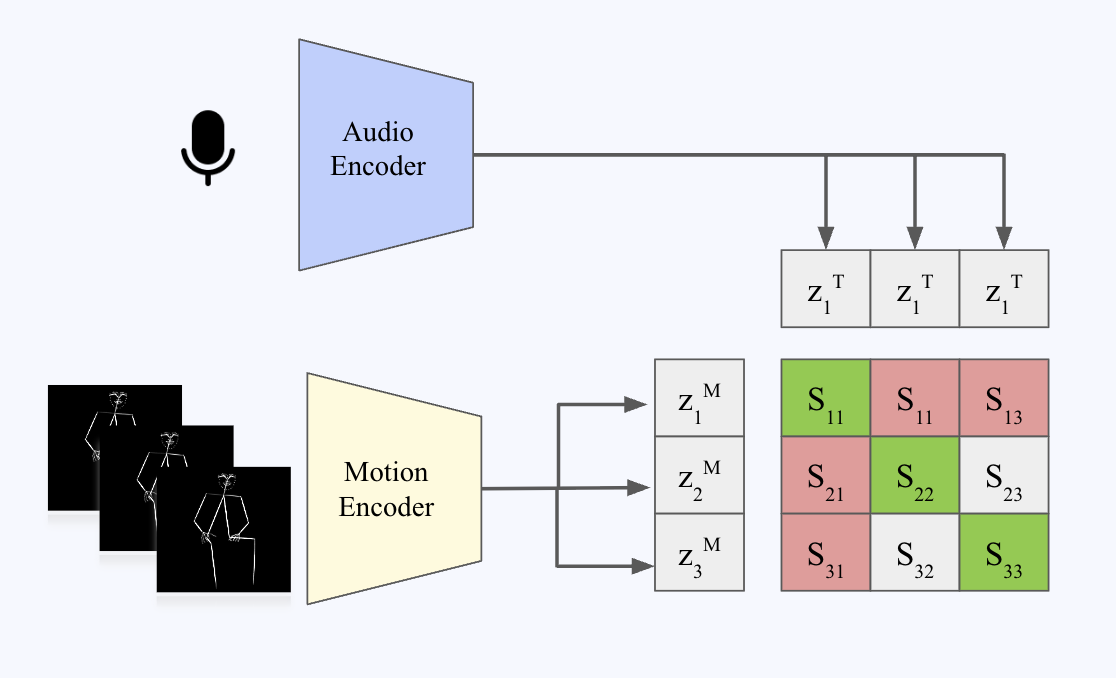
Express‑Eval is a CLIP-like model that plays a crucial role in evaluating the alignment between input audio and the corresponding generated human motion. It serves two primary purposes:
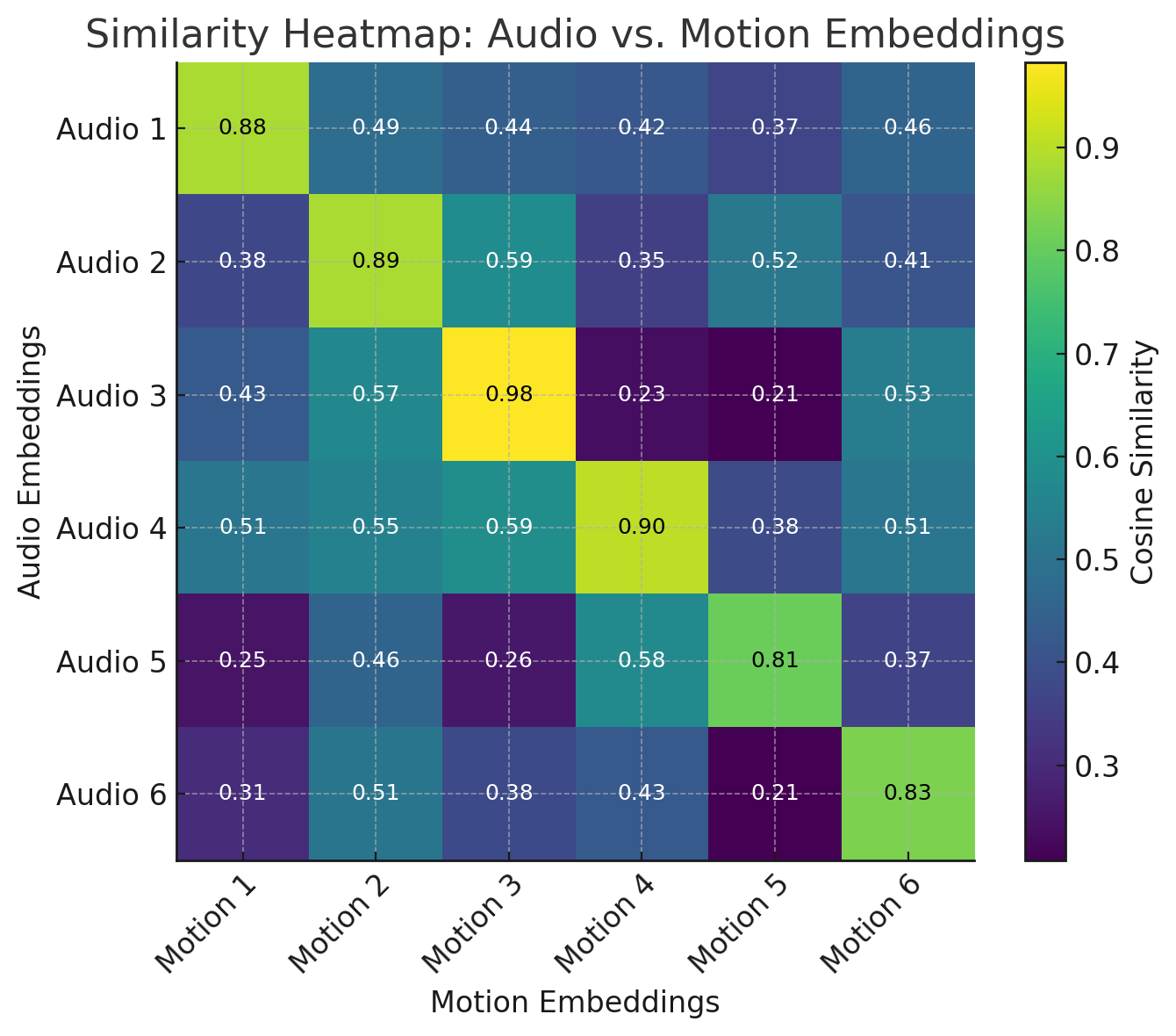
Express‑Eval is trained on a large, proprietary dataset of paired audio and motion sequences using a contrastive learning approach inspired by CLIP. The model learns joint audio-motion embeddings, and we compute alignment scores using cosine similarity between these representations. To ensure Express‑Eval can assess not just temporal alignment but also the expressive quality of the motion relative to the audio, we invested heavily in curating datasets that emphasize both accurate synchronization and performance diversity.
In the images below, we show a schematic illustration of Express‑Eval's architecture (left) and an example of training-time alignment scores between audio and motion (right).
Next, we give an example of three generations from the same audio sorted from left (best) to right (worst) by Express‑Eval.
Express‑Render
Express‑Render is a Diffusion Transformer (DiT) that translates the motion cues from Express‑Animate into photorealistic video-frames of the avatar. It synthesizes realistic facial expressions, head movements, and visual details that align precisely with the generated motion and input audio, ensuring that the avatar's appearance remains consistent and believable across extended sequences. We inject identity into the model by using tokenised reference images concatenated with the input visual tokens to be denoised.
Express‑Render generates videos at 1080p and 30fps, an important requirement for adoption of AI video generation in enterprise. Furthermore, Express‑Render generates arbitrarily long videos without identity drift. To the best of our knowledge, we are the first to demonstrate this at such high quality.
Due to these characteristics, the vanilla version of Express‑Render is slow and not practical for customer use. We therefore trained a distilled model that creates compelling results with just two diffusion steps, significantly reducing generation time.
Overall, Express‑Render can generate one minute of video at 1080p and 30fps in our production infrastructure in around 8 minutes. We will soon release Express‑Render-Turbo, which will be able to generate videos at 1080p and 30fps at a much faster rate.